In-Memory Storage Backends¶
ArcticDB can use a file-based LMDB backend, or a RAM-based in-memory storage, as alternatives to object storage such as S3 and Azure.
For temporary in-memory solutions, LMDB can be set up to write to tmpfs. As this guide will explore, with this solution multiple writers can access the database concurrently, and additionally benefit from increased performance when compared to LMDB writing to a permanent on-disk filesystem.
On Linux, the steps to set up a tmpfs filesystem are:
$ mkdir ./tmpfs_mount_point
$ sudo mount -t tmpfs -o size=1g tmpfs tmpfs_mount_point
And we can inspect that it is there with:
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.0G 0 1.0G 0% /somedir/tmpfs_mount_point
From ArcticDB you can connect to this filesystem with LMDB as you would usually:
import arcticdb as adb
import pandas as pd
ac_lmdb = adb.Arctic('lmdb:///somedir/tmpfs_mount_point')
lib = ac_lmdb.get_library('lib', create_if_missing=True)
lib.write('symbol', pd.DataFrame({'a': [1, 2, 3]})
print(lib.read('symbol').data)
which gives:
a
0 1
1 2
2 3
The equivalent instantiation for an in-memory store uses the URI 'mem://' as in:
ac_mem = adb.Arctic('mem://')
The ac_mem instance owns the storage, which lives only for the lifetime of the ac_mem Python object. Behind the
scenes, a Folly Concurrent Hash Map
is used as the key/value store. For test cases and experimentation, the in-memory backend is a good option.
If multiple processes want concurrent access to the same data, then we recommend using LMDB over a tmpfs.
How to handle concurrent writers?¶
Again, it should be noted that ArcticDB achieves its highest performance and scale when configured with an object storage backed (e.g. S3). Nevertheless, applications may want to concurrently write to LMDB stores. In-memory stores are not appropriate for this use case.
The following Python code uses multiprocessing
to spawn 50 processes that concurrently write to different symbols. (Non-staged parallel writes to the same
symbol are not supported).
# Code tested on Linux
import arcticdb as adb
import pandas as pd
from multiprocessing import Process, Queue
import numpy as np
lmdb_dir = 'data.lmdb'
num_processes = 50
data_KB = 1000
ncols = 10
nrows = int(data_KB * 1e3 / ncols / np.dtype(float).itemsize)
ac = adb.Arctic(f'lmdb://{lmdb_dir}')
ac.create_library('lib')
lib = ac['lib']
timings = Queue()
def connect_and_write_symbol(symbol, lmdb_dir, timings_):
ac = adb.Arctic(f'lmdb://{lmdb_dir}')
lib = ac['lib']
start = pd.to_datetime('now')
lib.write(
symbol,
pd.DataFrame(
np.random.randn(nrows, ncols),
columns=[f'c{i}' for i in range(ncols)]
)
)
timings_.put((start, pd.to_datetime('now')))
symbol_names = {f'symbol_{i}' for i in range(num_processes)}
concurrent_writers = {
Process(target=connect_and_write_symbol, args=(symbol, lmdb_dir, timings))
for symbol in symbol_names
}
# Start all processes
for proc in concurrent_writers:
proc.start()
# Wait for them to complete
for proc in concurrent_writers:
proc.join()
assert set(lib.list_symbols()) == symbol_names
timings_list = []
while not timings.empty():
timings_list.append(timings.get())
pd.DataFrame(timings_list, columns=['start', 'end']).to_csv('timings.csv')
Plotting the lifetimes of each process with matplotlib we get:
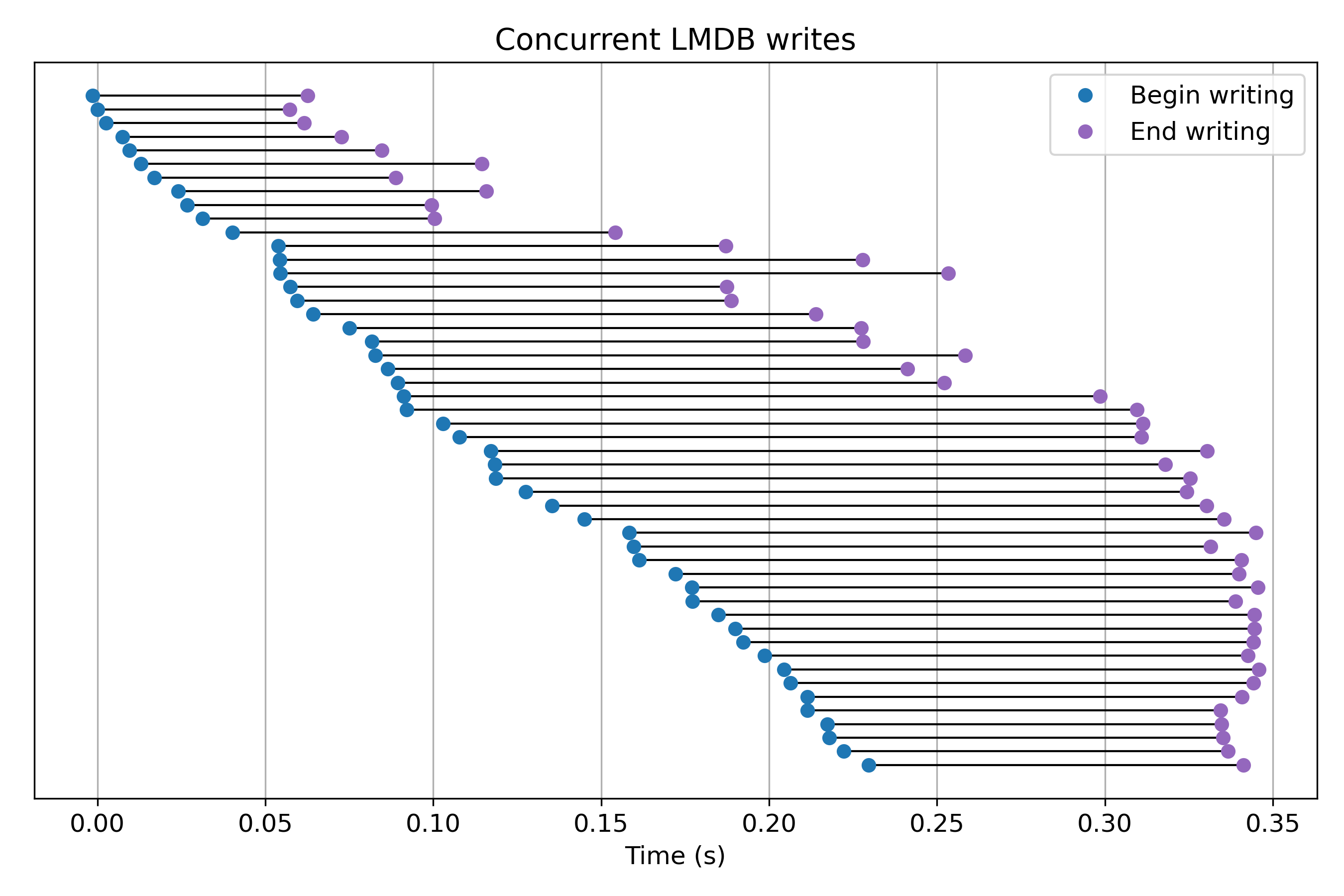
Explanation of graph: Each line segment represents the execution of a process writing to the shared LMDB backend.
File locks are repeatedly obtained and released by LMDB throughout the calls to lib.write(..).
The LMDB documentation homepage states that multi-threaded concurrency is also
possible. However as explained on this page we should not call
mdb_env_open() multiple times from a single process. Hence, since this is called in the Arctic instantiation,
the above code could not be transferred to a multi-threaded application.
Is LMDB on tmpfs any faster than LMDB on disk?¶
See the timing results below and the Appendix for the code to generate this data. The differences are not huge with tmpfs out-performing disk only for symbol writing operations. Nevertheless, tmpfs is clearly a better option for an ephemeral LMDB backend. We can also see that the in-memory store is significantly faster across the board as would be expected.
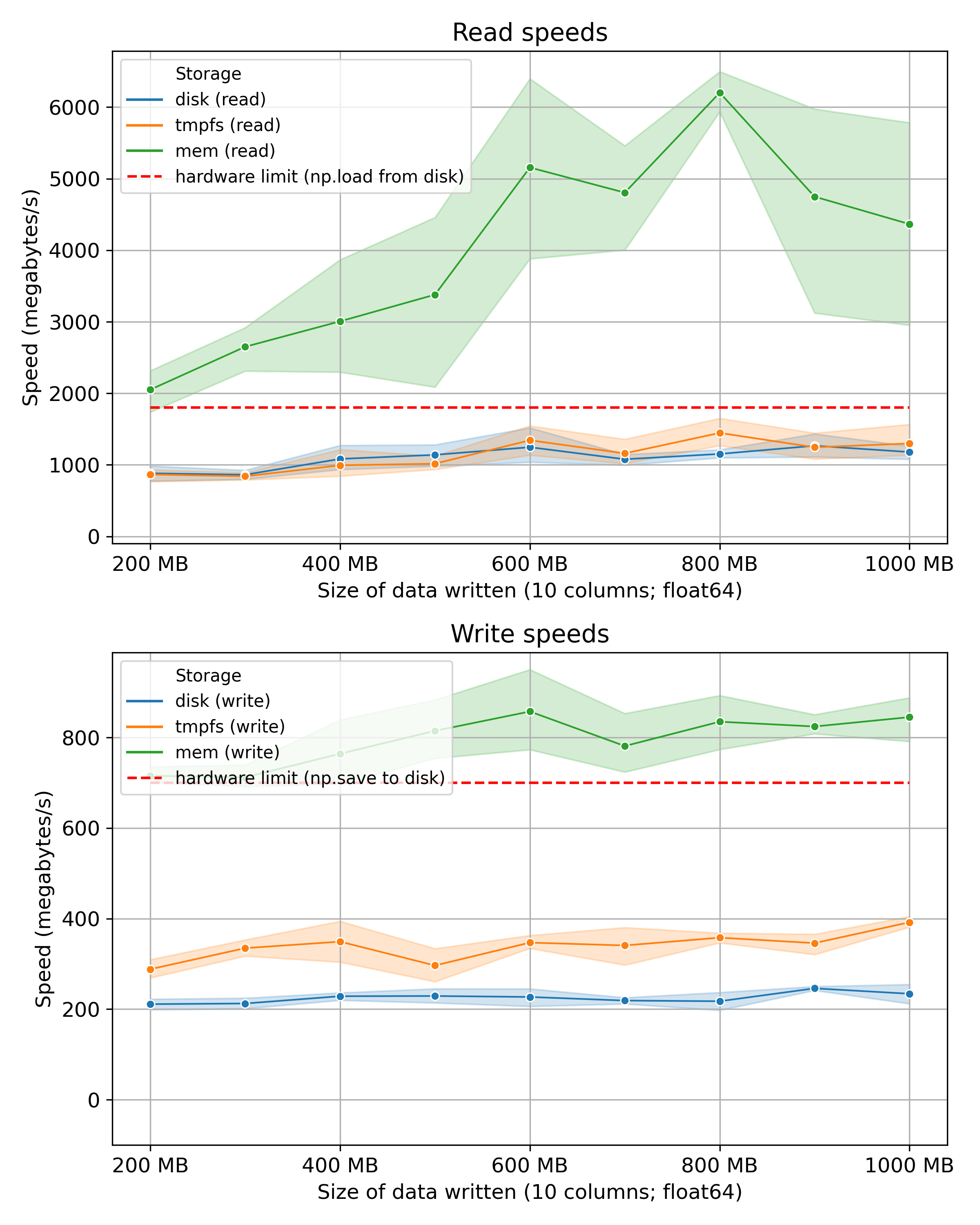
Note: the ranges are 95% confidence intervals based on five repeats for each data size. The hardware limits are for
writing to disk (not tmpfs) using the np.save and np.load functions. No data was sought for the RAM's hardware
limit.
Appendix: Profiling script¶
The profiling script used to generate the above graphs, and discussion of determining theoretical maximum read
and write speeds using fio have been moved to
this Wiki page.